Mnesia:Erlang 的数据库
设想咱们打算编写一款多用户游戏、构造一个新的 web 站点,或创建一个在线支付系统。咱们将可能需要一个数据库管理系统(DBMS)。
Mnesia 是一个以 Erlang 编写的数据库,用于要求苛刻的电信应用,同时是标准 Erlang 发行版的一部分。他可被配置为两个物理上分离节点上的 RAM 复制,提供快速的容错数据存储。他提供了事务能力,并带有其自己的查询语言。
Mnesia 速度极快,同时其可存储任何类型的 Erlang 数据结构。他还是高度可配置的。数据库的表可以被存储在内存中(出于速度原因)或磁盘上(出于持久性原因),而且这些表可以在不同的机器上复制,以提供容错行为。
查询初始数据库
在我们可完成任何事情前,我们必须创建个 Mnesia 数据库。咱们只需做一次这事。
1> mnesia:create_schema([node()]).
ok
2> init:stop().
ok
$ ls
Mnesia.nonode@nohost
mnesia:create_schema(NodeList) 会在 NodeList(这必须是个有效的 Erlang 节点列表)中的所有节点上,初始化一个新的 Mnesia 数据库。在我们的示例中,我们给出的节点列表是 [node()],即当前节点。Mnesia 将被初始化,并创建一个名为 Mnesia.nonode@nohost 的目录结构,以存储该数据库。
为何这个 DBMS 被叫做 Mnesia?
最初的名字叫 Amnesia。我们的一位老板不喜欢这个名字。他说:“你们可不能把他叫做 Amnesia -- 你们可不能有一个会忘记事情的数据库!” 于是,我们去掉了 A,这个名字就沿用下来了。
然后,我们从 Erlang shell 退出,执行操作系统的 ls 命令验证这点。
当我们以一个名为 joe 的分布式节点,重复这一练习时,我们会得到以下结果:
$ erl -name joe@host.xfoss.net
(joe@host.xfoss.net)1> mnesia:create_schema([node()]).
ok
(joe@host.xfoss.net)2> q().
ok
$ ls
Mnesia.joe@host.xfoss.net Mnesia.nonode@nohost
或者,我们可以在启动 Erlang 时,指向某个特定数据库。
$ erl -mnesia dir '"/home/hector/Documents/Mnesia.xfoss.com"' -name joe@host.xfoss.net
(joe@host.xfoss.net)1> mnesia:create_schema([node()]).
ok
(joe@host.xfoss.net)2> q().
ok
$ ls ~/Documents/Mnesia.xfoss.com
FALLBACK.BUP
其中 /home/hector/Documents/Mnesia.xfoss.com 是数据库将被存储于其下的目录名字。
数据库查询
在我们已创建了数据库后,我们就可以开始使用他。我们将从 Mnesia 的查询开始。当咱们看完之后,咱们可能会惊讶于 Mnesia 的查询,看起来很同时像 SQL 及列表综合,所以实际上要入门咱们几乎不需要学习什么。事实上,列表综合和 SQL 二者看起来很像并不奇怪。因为二者都基于数学的集合论。
在所有我们的示例中,我(作者)将假设咱们已创建了个有两个,分别叫作 shop 和 cost 表的数据库。这两个表包含的数据,在 表 8, shop 表和 表 9,cost 表 给出了。
Mnesia 中的表,是行的集合或包,其中每行都是一条 Erlang 的记录。要在 Mnesia 中表示这些表,我们需要一些定义了表中各个列的记录定义。这些定义如下所示:
| Item | Quantity | Cost |
|---|---|---|
| apple | 20 | 2.3 |
| orange | 100 | 3.8 |
| pear | 200 | 3.6 |
| banana | 420 | 4.5 |
| potato | 2456 | 1.2 |
表 8 -- shop 表
| Name | Price |
|---|---|
| apple | 1.5 |
| orange | 2.4 |
| pear | 2.2 |
| banana | 1.5 |
| potato | 0.6 |
-record(shop, {item, quantity, cost}).
-record(cost, {name, price}).
在可操作数据库前,我们需要创建一个数据库 schema、启动该数据库、添加一些数据表的定义以及停止数据库,并重启他。这些只需执行这一过程一次。下面即这段代码:
do_this_once() ->
mnesia:create_schema([node()]),
mnesia:start(),
mnesia:create_table(shop, [{attributes, record_info(fields, shop)}]),
mnesia:create_table(cost, [{attributes, record_info(fields, cost)}]),
mnesia:create_table(design, [{attributes, record_info(fields, design)}]),
mnesia:stop().
1> test_mnesia:do_this_once().
=INFO REPORT==== 16-Oct-2025::09:04:52.441325 ===
application: mnesia
exited: stopped
type: temporary
stopped
现在,我们就可以继续咱们的示例了。
选取表中的所有数据
下面是选择 shop 表中所有数据的代码。(对于你们中了解 SQL 的来说,每个代码片段都以显示要执行相应操作的等价 SQL 开头。)
%% SQL equivalent
%% SELECT * FROM shop;
demo(select_shop) ->
do(qlc:q([X || X <- mnesia:table(shop)]));
这段代码的核心,是对 qlc:q 的调用,其会将查询(他的参数)编译为用于查询数据库的某种内部形式。我们把生成的查询,传递给一个名为 do() 的函数,其定义在靠近 test_mnesia 底部处。他负责运行查询并返回结果。为便于从 erl 中调用所有这些,我们将其映射到函数 demo(select_shop)。
在可使用数据库前,我们需要一个启动他并加载表定义的例程。这个例程必须在使用数据库前被运行,但每个 Erlang 会话中其只能被运行一次。
start() ->
mnesia:start(),
mnesia:wait_for_tables([shop,cost,design], 20000).
...
example_tables() ->
[%% The shop table
{shop, apple, 20, 2.3},
{shop, orange, 100, 3.8},
{shop, pear, 200, 3.6},
{shop, banana, 420, 4.5},
{shop, potato, 2456, 1.2},
%% The cost table
{cost, apple, 1.5},
{cost, orange, 2.4},
{cost, pear, 2.2},
{cost, banana, 1.5},
{cost, potato, 0.6}
].
...
reset_tables() ->
mnesia:clear_table(shop),
mnesia:clear_table(cost),
F = fun() ->
foreach(fun mnesia:write/1, example_tables())
end,
mnesia:transaction(F).
现在我们就可以启动数据库,并进行一次查询了。
1> test_mnesia:start().
ok
2> test_mnesia:reset_tables().
{atomic,ok}
3> test_mnesia:demo(select_shop).
[{shop,pear,200,3.6},
{shop,apple,20,2.3},
{shop,orange,100,3.8},
{shop,potato,2456,1.2},
{shop,banana,420,4.5}]
注意:表中的行可以任意顺序出现。
这个示例中,建立查询的行如下:
qlc:q([X || X <- mnesia:table(shop)])
这看起来很像列表综合(参见 4.5 节,列表综合)。事实上,qlc 代表 query list, comprehensions, 查询列表综合。他是我们用以访问 Mnesia 数据库中数据的模组之一。
[X || X <- mnesia:table(shop)] 表示 “X 的一个列表,其中 X 取自 shop 这个 Mnesia 表"。X 的值,是 Erlang 的一些 shop 记录。
注意:qlc:q/1 的参数,必须是个列表综合的字面量,而不能是某个可求值为此类表达式的其他内容。因此,以下代码与这个示例中的代码, 并 不 等同:
Var = [X || X <- mnesia:table(shop)],
qlc:q(Var)
选择某个表中的数据
下面是个选取 shop 表中 item 和 quantity 列的查询:
%% SQL equivalent
%% SELECT item, quantity FROM shop;
demo(select_some) ->
do(qlc:q([{X#shop.item, X#shop.quantity} || X <- mnesia:table(shop)]));
4> test_mnesia:demo(select_some).
[{pear,200},
{apple,20},
{orange,100},
{potato,2456},
{banana,420}]
在上一各查询中,X 的值为 shop 类型的一些记录。当咱们回顾 5.2 小节 记录下的命名元组项目 中,描述的记录语法时,咱们就会记得 X#shop.item 指向了 shop 记录的 item 字段。因此,元组 {X#shop.item, X#shop.quantity} 便是 X 的 item 和 quantity 字段的元组。
有条件地选取表中的数据
下面是个列出 shop 表中,库存数量小于 250 的所有物品的查询。也许我们将使用这个查询,决定要重新订购哪些物品。请注意,其中的条件,是如何作为列表综合的一部分自然描述的。
%% SQL equivalent
%% SELECT shop.item FROM shop
%% WHERE shop.quantity < 250;
demo(reorder) ->
do(qlc:q([X#shop.item || X <- mnesia:table(shop),
X#shop.quantity < 250
]));
5> test_mnesia:demo(reorder).
[pear,apple,orange]
选取两个表中的数据(联合)
现在我们假设,我们打算只重新订购库存少于 250 件,且价格低于 2.0 个货币单位的物品。要完成这一操作,我们需要访问两个表。下面是这个查询:
%% SQL equivalent
%% SELECT shop.item
%% FROM shop, cost
%% WHERE shop.item = cost.name
%% AND cost.price < 2
%% AND shop.quantity < 250
demo(join) ->
do(qlc:q([X#shop.item || X <- mnesia:table(shop),
X#shop.quantity < 250,
Y <- mnesia:table(cost),
X#shop.item =:= Y#cost.name,
Y#cost.price < 2
])).
这里的关键,是 shop 表中物品名称,与 cost 表中名称之间的连接。
X#shop.item =:= Y#cost.name
添加与移除数据库中的数据
同样,我们将假设我们已经创建了数据库并定义了个 shop 表。现在我们打算从表中添加或删除某行。
添加行
我们可如下往 shop 表中添加一行:
add_shop_item(Name, Quantity, Cost) ->
Row = #shop{item=Name, quantity=Quantity, cost=Cost},
F = fun() ->
mnesia:write(Row)
end,
mnesia:transaction(F).
这个函数会创建一条 shop 记录,并将其插入该表。
1> test_mnesia:start().
ok
2> test_mnesia:reset_tables().
{atomic,ok}
%% list the shop table
3> test_mnesia:demo(select_shop).
[{shop,pear,200,3.6},
{shop,apple,20,2.3},
{shop,orange,100,3.8},
{shop,potato,2456,1.2},
{shop,banana,420,4.5}]
%% add a new row
4> test_mnesia:add_shop_item(orange, 236, 2.8).
{atomic,ok}
%% list the shop table again so we can see the change
5> test_mnesia:demo(select_shop).
[{shop,pear,200,3.6},
{shop,apple,20,2.3},
{shop,orange,236,2.8},
{shop,potato,2456,1.2},
{shop,banana,420,4.5}]
注意:shop 表的 主键,是该表中的第一列,即 shop 记录中的 item 字段。该表为 “集合” 类型(请参阅 19.1 节,数据表的类型 中集合与包类型的讨论)。当新创建的记录主键,有着与数据库表中某个既有行同样的主键时,他将覆盖该行;否则,一条新记录将被创建。
移除行
要移除某行,我们需要知道该行的对象 ID(OID)。这是由表的名字和主键的值组成。
remove_shop_item(Item) ->
Oid = {shop, Item},
F = fun() ->
mnesia:delete(Oid)
end,
mnesia:transaction(F).
6> test_mnesia:remove_shop_item(pear).
{atomic,ok}
%% list the table -- the pear has gone
7> test_mnesia:demo(select_shop).
[{shop,apple,20,2.3},
{shop,orange,236,2.8},
{shop,potato,2456,1.2},
{shop,banana,420,4.5}]
8> mnesia:stop().
=INFO REPORT==== 16-Oct-2025::14:26:47.497779 ===
application: mnesia
exited: stopped
type: temporary
stopped
Mnesia 的事务
当我们添加或移除数据库中的数据,或执行某个查询时,我们如下编写的代码:
do_something(...) ->
F = fun() ->
% ...
mnesia:write(Row)
% ... or ...
mnesia:delete(Oid)
% ... or ...
qlc:e(Q)
end,
mnesia:transaction(F)
其中 F 是个零参数的函数。在 F 内部,我们调用了 mne-sia:write/1、mnesia:delete/1 或 qlc:e(Q)(其中 Q 是以 qlc:q/1 编译过的一个查询)的某种组合。建立了这个 fun 后,我们会调用 mnesia:transaction(F),他会计算这个 fun 中的表达式序列。
事务会防止错误的程序代码,但更重要的是会防止对数据库的并发访问。设想我们有两个试图同时访问同一数据的进程。例如,假设我(作者)在我的银行账户里有 10 美元。现在设想两个试图同时从该账户中,提取 8 美元的人。我会希望这两个事务中一个成功,另一个失败。
这正是 mnesia:transaction/1 所提供的保证。在某个特定事务中,对数据库中表的全部读写,都会要么成功,要么全都失败。当全都失败时,该事务即被称作失败。当该事务失败时,就不会有任何更改将在该数据库上执行。
Mnesia 为此所使用的策略,是 悲观锁 的一种形式。当 Mnesia 的事务管理器访问某个表时,他会根据上下文,尝试锁定记录或整个表。当其发现这可能导致死锁时,他会立即中止事务,并撤销其所做的任何更改。
当事务由于其他进程正访问数据,而已开始就失败时,系统会等待一小段时间,然后重试该事务。这样做的一个后果,是该事务 fun 内的代码,可能会被执行很多次。
出于这一原因,事务 fun 中的代码,不应执行任何有副作用的事情。例如,当我们打算写出以下代码时:
F = fun() ->
...
io:format("reading ..."), %% don't do this
...
end,
mnesia:transaction(F),
我们可能会得到大量输出,因为这个 fun 可能会被重试很多次。
注意 1:mnesia:write/1 和 mnesia:delete/1,都只应在某个由 mnesia:transaction/1 处理的 fun 中调用。
注意 2:咱们绝不应该在 Mnesia 的访问函数(mnesia:write/1、mnesia:delete/1 等)中,编写显式捕获异常的代码,因为 Mnesia 的事务机制本身,依赖于这些函数在失败时抛出异常。当咱们捕获了这些异常,并试图咱们自己处理他们时,咱们将破坏事务机制。
中止事务
我们商店附近有个农场。农场主种了苹果。农场主喜欢橘子,他会用苹果付橘子的钱。目前的比率是两个苹果换一个橘子。因此,要买 N 个橘子,农场主就要支付 2*N 个苹果。下面是个当农场主买了些橘子时,更新数据库的函数:
farmer(Nwant) ->
%% Nwant = Number of oranges the farmer wants to buy
F = fun() ->
%% find the number of apples
[Apple] = mnesia:read({shop,apple}),
Napples = Apple#shop.quantity,
Apple1 = Apple#shop{quantity = Napples + 2*Nwant},
%% update the database
mnesia:write(Apple1),
%% find the number of oranges
[Orange] = mnesia:read({shop,orange}),
NOranges = Orange#shop.quantity,
if
NOranges >= Nwant ->
N1 = NOranges - Nwant,
Orange1 = Orange#shop{quantity=N1},
%% update the database
mnesia:write(Orange1);
true ->
%% Oops -- not enough oranges
mnesia:abort(oranges)
end
end,
mnesia:transaction(F).
这段代码写得非常愚蠢,因为我(作者)想要展示事务机制的工作原理。首先,我(作者)要更新数据库中苹果的数量。这是我在检查橙子数量 前 完成的。我执行这个操作的原因,是要展示当事务失败时,这一更改会被 “撤销”。通常情况下,我(作者)会将写回橙子和苹果数据到数据库,延迟到我已确定我有着足够橙子之后。
我们来在操作中展示这一点。早上,农场主来了商店,并买了 50 个橘子。
1> test_mnesia:start().
ok
2> test_mnesia:reset_tables().
{atomic,ok}
3> test_mnesia:demo(select_shop).
[{shop,pear,200,3.6},
{shop,apple,20,2.3},
{shop,orange,100,3.8},
{shop,potato,2456,1.2},
{shop,banana,420,4.5}]
4> test_mnesia:farmer(50).
{atomic,ok}
5> test_mnesia:demo(select_shop).
[{shop,pear,200,3.6},
{shop,apple,120,2.3},
{shop,orange,50,3.8},
{shop,potato,2456,1.2},
{shop,banana,420,4.5}]
下午,农夫打算再买 100 个橘子(天哪,这家伙真爱吃橘子)。
6> test_mnesia:farmer(100).
{aborted,oranges}
7> test_mnesia:demo(select_shop).
[{shop,pear,200,3.6},
{shop,apple,120,2.3},
{shop,orange,50,3.8},
{shop,potato,2456,1.2},
{shop,banana,420,4.5}]
当事务失败时(在我们调用 mnesia:abort(Reason) 后),由 mnesia:write 执行的那些更改会被撤销。因此,数据库状态就被恢复到了我们进入该事务前的状态。
加载测试数据
现在我们知道事务的工作原理,那么我们就可以看看,加载测试数据的代码。
函数 test_mnesia:example_tables/0 被用来提供初始化数据库表的数据。其中元组的第一个元素,是表的名字。其后是以原始记录定义中所给出顺序一致的数据表数据。
example_tables() ->
[%% The shop table
{shop, apple, 20, 2.3},
{shop, orange, 100, 3.8},
{shop, pear, 200, 3.6},
{shop, banana, 420, 4.5},
{shop, potato, 2456, 1.2},
%% The cost table
{cost, apple, 1.5},
{cost, orange, 2.4},
{cost, pear, 2.2},
{cost, banana, 1.5},
{cost, potato, 0.6}
].
随后是将示例表中数据,插入 Mnesia 的代码。此代码只是针对由 example_tables/1 所返回列表中的每个元组,调用 mnesia:write。
reset_tables() ->
mnesia:clear_table(shop),
mnesia:clear_table(cost),
F = fun() ->
foreach(fun mnesia:write/1, example_tables())
end,
mnesia:transaction(F).
函数 do()
由 demo/1 调用的函数 do(),稍微有些复杂。
do(Q) ->
F = fun() -> qlc:e(Q) end,
{atomic, Val} = mnesia:transaction(F),
Val.
这个函数在一次 Mnesia 事务中,调用了 qlc:e(Q)。其中 Q 是个已编译的 QLC 查询,qlc:e(Q) 会执行这个查询,并以列表形式返回该查询的所有答复。返回值 {atomic, Val} 表示这个事务以值 Val 成功了。Val 为事务函数的值。
在数据表中存储复杂数据
使用传统 DBMS 的一个缺点是,咱们只可在数据表列中,存储有限的数据类型。咱们可存储整数、字符串、浮点数等。但当咱们想要存储某个复杂对象时,那咱们就麻烦了。因此,举例来说,当咱们是名 Java 程序员时,在 SQL 数据库中存储 Java 对象,就相当麻烦。
Mnesia 设计用于存储 Erlang 的数据结构。事实上,咱们可将任何咱们想要的 Erlang 数据结构,存储在 Mnesia 数据表中。
为演示这点,我们将设想一些建筑师想把他们的设计,存储在一个 Mnesia 数据库中。首先,我们必须定义一个记录表示他们设计的记录。
-record(design, {id, plan}).
然后我们就可以定义个将一些涉及,添加到数据库的函数。
add_plans() ->
D1 = #design{id = {joe,1},
plan = {circle,10}},
D2 = #design{id = fred,
plan = {rectangle,10,5}},
D3 = #design{id = {jane,{house,23}},
plan = {house,
[{floor,1,
[{doors,3},
{windows,12},
{rooms,5}]},
{floor,2,
[{doors,2},
{rooms,4},
{windows,15}]}]}},
F = fun() ->
mnesia:write(D1),
mnesia:write(D2),
mnesia:write(D3)
end,
mnesia:transaction(F).
现在,我们便可将一些设计,添加到数据库。
1> test_mnesia:start().
ok
2> test_mnesia:add_plans().
{atomic,ok}
现在我们有了数据库中的一些规划。我们可以下面的访问函数,提取这些规划:
get_plan(PlanId) ->
F = fun() -> mnesia:read({design, PlanId}) end,
mnesia:transaction(F).
3> test_mnesia:get_plan(fred).
{atomic,[{design,fred,{rectangle,10,5}}]}
4> test_mnesia:get_plan({jane, {house,23}}).
{atomic,[{design,{jane,{house,23}},
{house,[{floor,1,[{doors,3},{windows,12},{rooms,5}]},
{floor,2,[{doors,2},{rooms,4},{windows,15}]}]}}]}
正如咱们所见,数据库的键和提取到的记录,都可以是任意 Erlang 项。
在技术术语下,我们讲在数据库中的数据结构,与咱们编程语言中的数据结构间,不存在 阻抗失配。这意味着将复杂数据结构插入数据库,及从数据库中删除,会非常快。
数据表类型与位置
我们可将 Mnesia 的数据表配置为多种方式。首先,数据表可在内存中,或在磁盘上(或两者兼而有之)。其次,数据表可位于一台机器上,或复制在多台机器上。
当我们设计咱们的数据表时,我们必须考虑我们打算在表中存储数据的类型。下面是数据表的一些属性:
-
RAM 数据表
这些数据表非常快。他们中的数据是 瞬态的,因此当机器崩溃或我们停止 DBMS 时,数据就会丢失。
-
磁盘数据表
磁盘数据表应能在崩溃后继续幸存(前提是磁盘未受物理损坏)。
当某个 Mnesia 事务写入某个数据表,而该表为存储在磁盘上的时,实际发生的情况,是该事务的数据会首先写入一个磁盘日志。这个磁盘日志会持续增长,同时这个磁盘日志中的信息,就会定期与数据库中别的数据合并,进而该磁盘日志中的条目会被清除。当系统崩溃时,那么下次系统被重启时,出于一致性目的,这个磁盘日志会被检查,同时在数据库可用前,日志中任何未完成条目,都会被添加到数据库中。一旦某个事务已经成功,其中数据就会被正确写入磁盘日志,而当系统在此之后失效,那么当系统下次重启时,该事务中所做出的更改,都应幸免于这次崩溃。
当系统在某次事务期间崩溃,那么对数据库所做的更改应会丢失。
分片表
Fragmented Tables
Mnesia 支持 “分片” 表(数据库术语中的 水平分区,horizontal partitioning)。这一特性是为实现一些超大数据表设计的。数据表被分割成存储在不同机器上的一些分片。这些分片本身就是一些 Mnesia 数据表。分片可像其他数据表一样,被复制、有着索引等。
更多详情,请参阅 Mnesia 用户指南 。
在使用 RAM 表前,咱们需要进行一些实验,确定整个表是否适合放入物理内存。当 RAM 表无法放入物理内存时,系统将频繁翻页,这将不利于性能。
RAM 表是瞬态的,因此当我们打算构建某个容错应用时,我们将需要在磁盘上复制该 RAM 表,或在第二台机器上将其复制为 RAM 表或磁盘表,或两者兼而有之。
创建数据表
要创建一个数据表,我们就调用 mnesia:create_table(Name,ArgS),其中 ArgS 是个 {Key,Val} 的元组列表。当数据表成功创建时,create_table 会返回 {atomic, ok};否则他会返回 {aborted, Reason}。create_table 的一些常见参数如下:
-
Name这是数据表的名字(一个原子)。依惯例,他是某个 Erlang 记录的名字 -- 数据表的行,将是该记录的一些实例;
-
{type, Type}这个参数指定数据表的类型。
Type为set、ordered_set或bag之一。这些类型的含义与 19.1 节 表的类型 中描述相同的意义; -
{disc_copies, NodeList}NodeList是该数据表将被存储的磁盘副本所在 Erlang 节点的列表。当我们使用这一选项时,系统将同样在我们执行此操作的节点上,创建该表的 RAM 副本。在一个节点上有个
disc_copies类型的复制表,并在另一节点上有着存储为不同类型的同一个表,是可行的。当我们希望达到如下目标时,这种做法是可取的:- 读操作要特别快,并要在 RAM 中完成;
- 写操作要对持久存储完成。
-
{ram_copies, NodeList}NodeList是个 Erlang 节点列表,数据表的 RAM 副本将存储在其上; -
{disc_only_copies, NodeList}NodeList是一个 Erlang 节点列表,仅数据的磁盘副本被被存储于其上。这些数据表没有 RAM 副本,访问较慢; -
{attributes, AtomList}这是某个特定表中,值的列名字列表。请注意,要创建一个包含 Erlang 记录
xxx的数据表,我们可以使用{attributes, record_info(fields,xxx)}这种语法(或者,我们可指定一个显式的记录字段名字列表)。
注意:create_table 的选项比我(作者)这里介绍的要多。有关全部选项的详细信息,请参阅 mnesia 的手册页面。
数据表属性的常见组合
在下文中,我们将假定 Attrs 是个 {attributes,...} 元组。
下面是涵盖了最常见情况的,一些常用数据表配置选项:
-
mnesia:create_table(shop, [Attrs])- 这会在单一节点上,构造一个驻留内存的数据表;
- 当节点崩溃时,该数据表将会丢失;
- 这是所有数据格中最快的;
- 该数据表必须装入内存。
-
mnesia:create_table(shop, [Attrs, {disc_copies, [node()]}])- 这会在单一节点上,构造一个驻留内存表以及一个磁盘副本;
- 当节点崩溃时,该表将从磁盘恢复;
- 这种数据表有着高速的读访问,但写访问较慢;
- 该数据表应可装入内存。
-
mnesia:create_table(shop, [Attrs, {disc_only_copies, [node()]}])- 这种参数组合,会在单一节点上构造一个仅磁盘的副本;
- 这会用于数据表太大,无法装入内存时;
- 相比带有驻留内存的副本,其有着较慢的访问时间。
-
mnesia:create_table(shop, [Attrs, {ram_copies, [node(), someOtherNode()]}])- 这会构造两个节点上的驻留内存数据表;
- 当两个节点都崩溃时,该数据表丢失;
- 该数据表必须要装入内存;
- 在两个节点上该数据表都能被访问。
-
mnesia:create_table(shop, [Attrs, {disc_copies, [node(), someOtherNode()]}])- 这会构造多个节点上的磁盘拷贝;
- 在任何节点崩溃后,我们都可恢复运行;
- 这会幸免于任何节点的失效。
数据表的行为
当某个表在多个 Erlang 节点上被复制了时,他会尽可能同步。当某个节点崩溃时,系统仍将工作,但副本的数量将减少。当崩溃节点重新上线时,他将与副本被留存下来的其他节点重新同步。
注意:当运行 Mnesia 的节点停止发挥作用时,Mnesia 可能会变得过载。若咱们正使用一台进入休眠状态的笔记本电脑,当他重新启动时,Mnesia 可能变得暂时超载,并产生一些告警消息。我们可以忽略这些消息。
数据表查看器
要查看我们存储在 Mnesia 中的数据,我们可使用构建在 “observer” 应用中的数据表查看器。请以命令 observer:start() 启动 observer,然后单击 “Table Viewer” 选项卡。现在选择 observer 控制菜单中的 “View > Mnesia Tables”。咱们将看到一个如下所示的数据表列表:
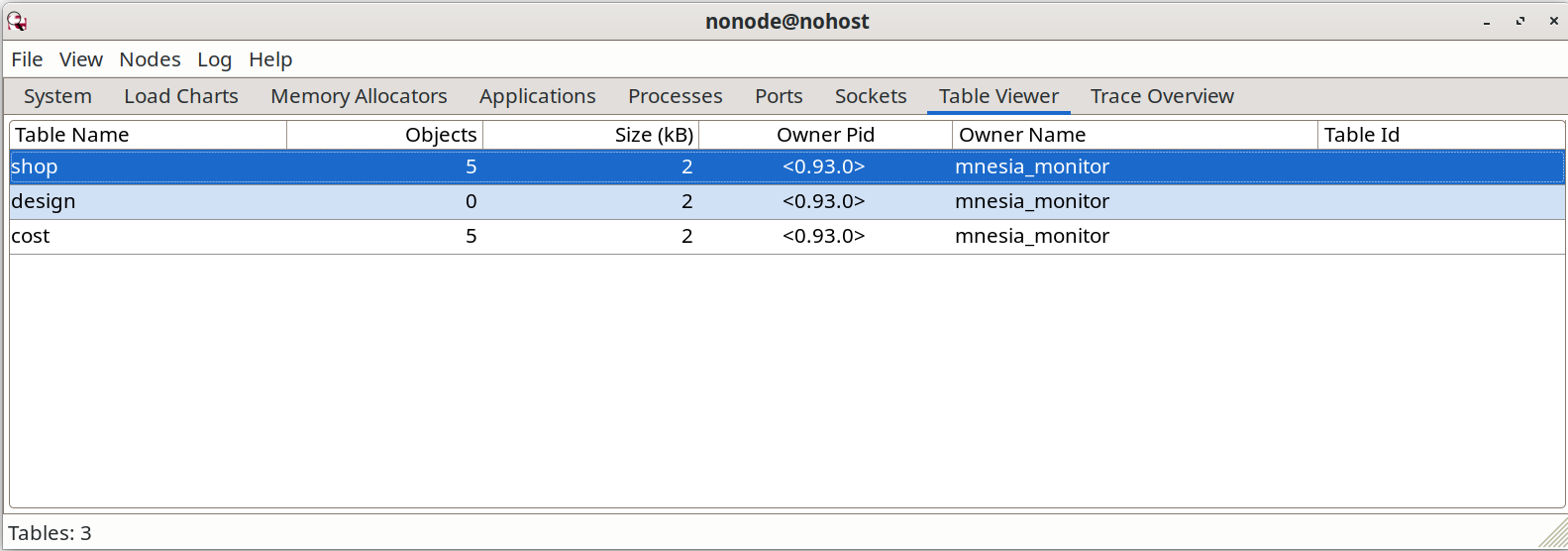
双击其中的 shop 条目,一个新视窗就打开了。
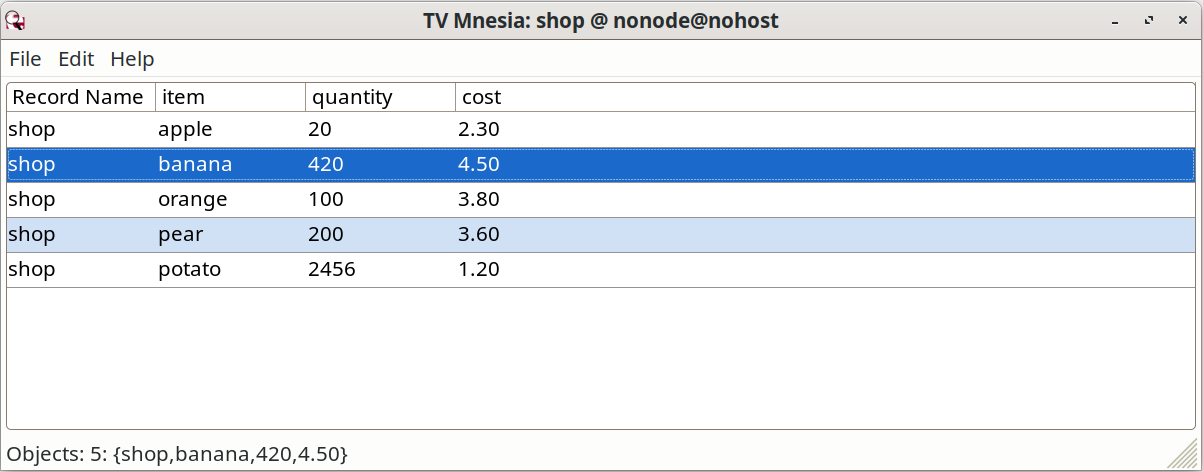
使用这个 observer,咱们可查看表格、检查系统状态、查看进程等等。
深入挖掘
希望我(作者)已经吊起了咱们对 Mnesia 的胃口。Mnesia 是个非常强大的 DBMS。自 1998 年以来,他已在爱立信交付的许多要求苛刻电信应用中,投入生产用途。
由于这是本关于 Erlang 而非 Mnesia 的书,我(作者)只能举几个使用 Mnesia 的最常见方式的示例。我(作者)在本章中展示的那些技术,都是我自己使用的一些技术。实际上,除了向咱们展示的技术外,我并没有用到(或掌握)更多的了。但是,通过我(作者)已展示的这些技术,咱们就可以获得很多乐趣,并构建出一些相当复杂的应用。
我(作者)省略的主要方面如下:
-
备份与恢复
Mnesia 有一系列用于配置备份操作,实现不同类型灾难恢复的选项;
-
脏操作
Mnesia 允许进行数种 脏 操作(
dirty_read、dirty_write等等)。这是一些在某个事务上下文外,执行的操作。他们属于可在咱们知道咱们的应用是单线程的,或在别的特殊情形下使用的一些危险操作。脏操作被用于效率原因。 -
SNMP 数据表
Mnesia 有着一个内置的 SNMP 数据表类型。这个类型使得实现 SNMP 管理系统非常容易。
Mnesia 的权威参考,是 Erlang 发行版主站点上的 Mnesia User's Guide。此外,Mnesia 发行版中的 examples 子目录(在我(作者)的机器上是 /usr/local/lib/erlang/lib/mnesia-X.Y.Z/examples)有着一些 Mnesia 示例。
现在我们已经完成了有关数据存储的两章内容。在下一章中,我们将学习调试、跟踪及性能优化的一些方法。
练习
-
设想咱们要构造一个其中用户可留下有关 Erlang 优秀程序建议的网站。请构造一个有三个表(
users、tips和abuse)的 Mnesia 数据库,存储该网站所需的全部数据。users表应存储用户账户数据(姓名、电子邮件地址、密码等);tips表应存储有关有价值网站的建议(如网站 URL、描述、评论日期等)。abuse表应存储尝试阻止该网站被滥用的数据(网站访问 IP 地址、网站访问次数等数据)。请将数据库配置为在一台机器上,以一个内存及一个磁盘拷贝运行。请编写读取、写入和列出这些数据表的例程;
-
请继续前一练习,但要对两台机器,将数据库配置为带有复制的内存和磁盘拷贝。尝试在一台机器上发起更新,然后让这台机器崩溃,同时检查咱们可否在第二台机器上继续访问该数据库;
-
请编写个当某名用户在一天内提交了十条以上建议,或在过去一天内从三个以上 IP 地址登录时,拒绝接受建议的查询。
请测量查询数据库要用多长时间。